I moderna webbanalys-verktyg som Matomo finns information om hur snabb din webbplats är. Rent utav information som är ganska nära hur webbplatsen upplevs av verkliga användare. Låt oss hacka runt i denna datakälla!
Sammanfattning:
- Vi tittar på en metod som mixar den laddningstid verkliga besökare har på en webbplats med syntetiska tester för att reda ut potentiella åtgärder för långsammare webbsidor.
- Poängen med att utgå ifrån RUM-data i Matomo är att börja med faktiska användares upplevelser, genom syntetiska metoder bekräftar vi problemen och tar reda på vad som brister på respektive webbsida.
- Genom bearbetning av testresultatet från Webperf Core får vi en agerbar lista med potentiella prestandaproblem att undersöka vidare.
Avsnitt:
- Hur kompletterar Matomo egentligen Webperfs prestandatester? RUM-data!
- Exportera RUM-prestanda från Matomo och fortsätt med Webperf Core
På mitt 8-17-jobb har jag ständigt anledning att titta extra noga i vilka API:er (läs; tekniska möjligheter för integration) och exportmöjligheter som finns i Matomo och alla andra webbanalysverktyg jag använder. Ett API är en integrationspunkt och med viss förberedelse behöver det inte vara särskilt mycket teknik inblandat för att dra nytta av det i vardagen. Ett aktuellt exempel är Model Context Protocol som kan ge ett konverserande gränssnitt till de olika verktyg du har.
→ När analysverktyg börjar prata samma språk: Model Context Protocol för webbanalytiker (Webperf)
Hur kompletterar Matomo egentligen Webperfs prestandatester? RUM-data!
Skillnaden stavas RUM (Real-User Monitoring). De tester som Webperf kör är av typen som kallas syntetiska tester och det kallas så för att testet inte har en faktisk användare inblandad. Med syntetiska tester brukar vi ofta försöka köra dem under realistiska omständigheter som liknar vad en verklig användare kan uppleva. Men det är ändå inte samma sak. Det är en simulering!
En annan skillnad är att syntetiska tester ofta är enskilda stickprov och RUM-tester görs kontinuerligt i samband med att webbplatsen används över dygnets alla timmar (och under verkliga omständigheter). Det är inte lätt för oss med innifrånperspektiv som utvecklare eller webbansvariga att förutse den här verkligheten våra användare möter. Särskilt då vi själva tenderar att testa via fiberuppkoppling, på kontorstid och en dator.
Syntetiska tester och RUM-tester passar bra ihop!
Syntetiska tester har vi för att identifiera problem och jämföra dem över tid. Syntetiska tester har också möjligheten att göra en hälsokontroll innan verkliga användare drabbas. RUM-tester har vi för att få perspektiv om hur det ser ut för våra faktiska användare.
→ Syntetiska tester vs RUM-tester - hur ska jag tänka? (Webperf)
Om vi utforskar den datakälla som Matomo har för hastighet styr vi mot Beteende → Prestanda i menyn. Då ser det ut så här:
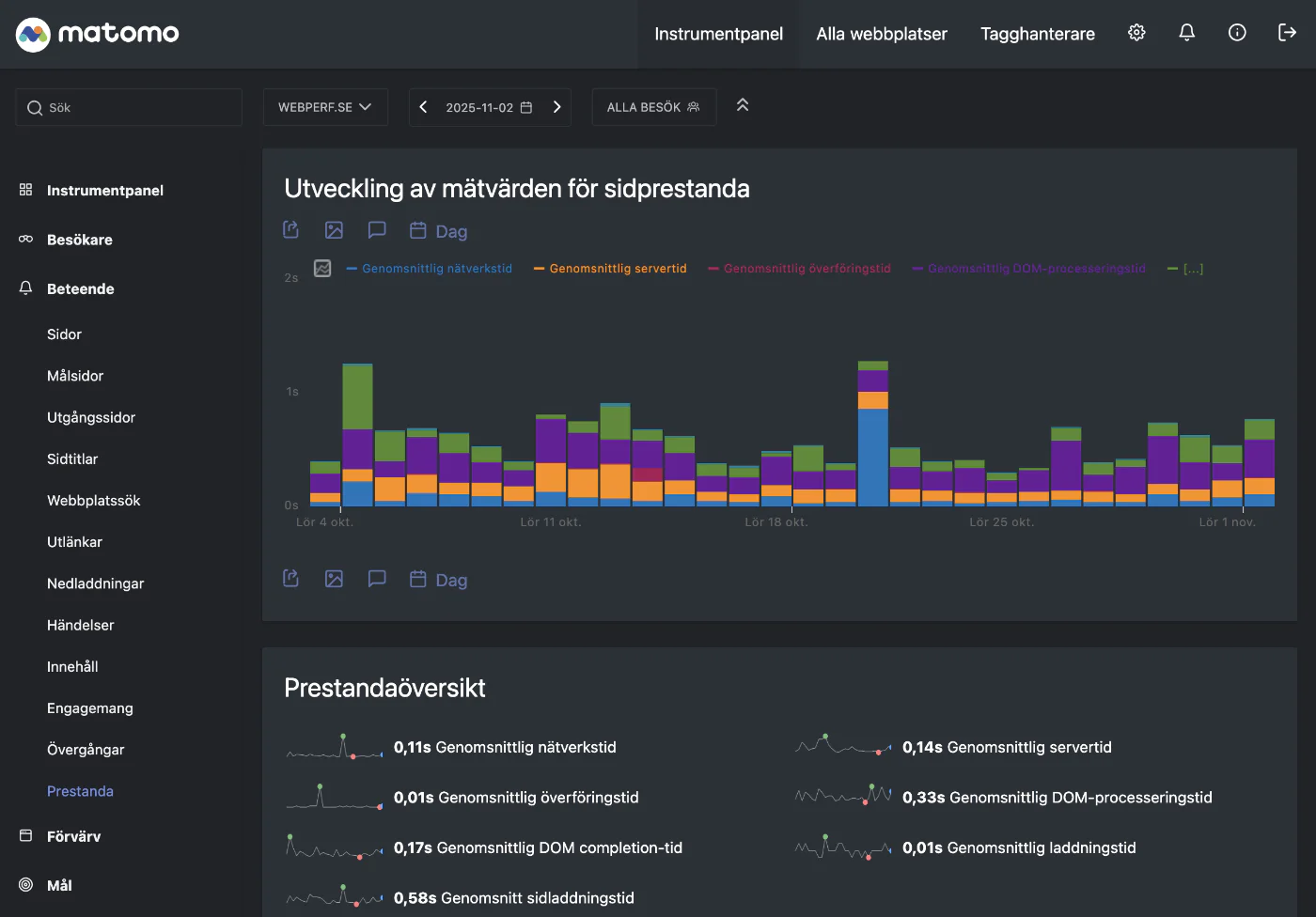
Det är en utvecklingsgraf där vi kan se variation över tid. Färgerna inom respektive stapel berättar vilket moment av sidladdningen som tar mycket tid. Boxen nedanför, Prestandaöversikt
, sammanfattar översiktlig statistik i form av genomsnitt, men bara för den enskilda dag jag valt i datumväljaren (2:a november).
Det som utvecklingsgrafen gör riktigt bra är att visuellt stötta en analytiker att upptäcka eventuella avvikelser. Du kanske precis som jag undrar över den där höga blå stapeln, den 21:a oktober? Det är bara att välja det datumet och utforska den data som finns, för de detaljerna finns i boxen Webbadresser (eller Sidtitlar) en bit ner. Där får du en mix av möjligheter. Dels att du vet exakt var på webbplatsen det gäller, dels att du kan välja ett enskilt mått att fokusera på.
Det här att utforska sin webbanalysdata är vad som på engelska kallas för en exploratory data analysis. Det kan vara svårt i verktyg som Matomo, då det inte har ambitionen att vara Business Intelligence-verktyg. Men med en lösning för att återbearbeta rådata är det faktiskt fullt möjligt att ganska snabbt få svar även på nya typer av frågor. Det må vara frustrerande att behöva tänka till på förhand med hur Matomo är designat. Samtidigt är det väldigt hållbart genom att inte killgissa vilka sammanställningar du kan behöva.
Långsamt på Webperf.se enligt Matomo
I nedan bild ser du URL:ar på Webperf.se sorterat efter långsammaste Genomsnitt sidladdningstid.
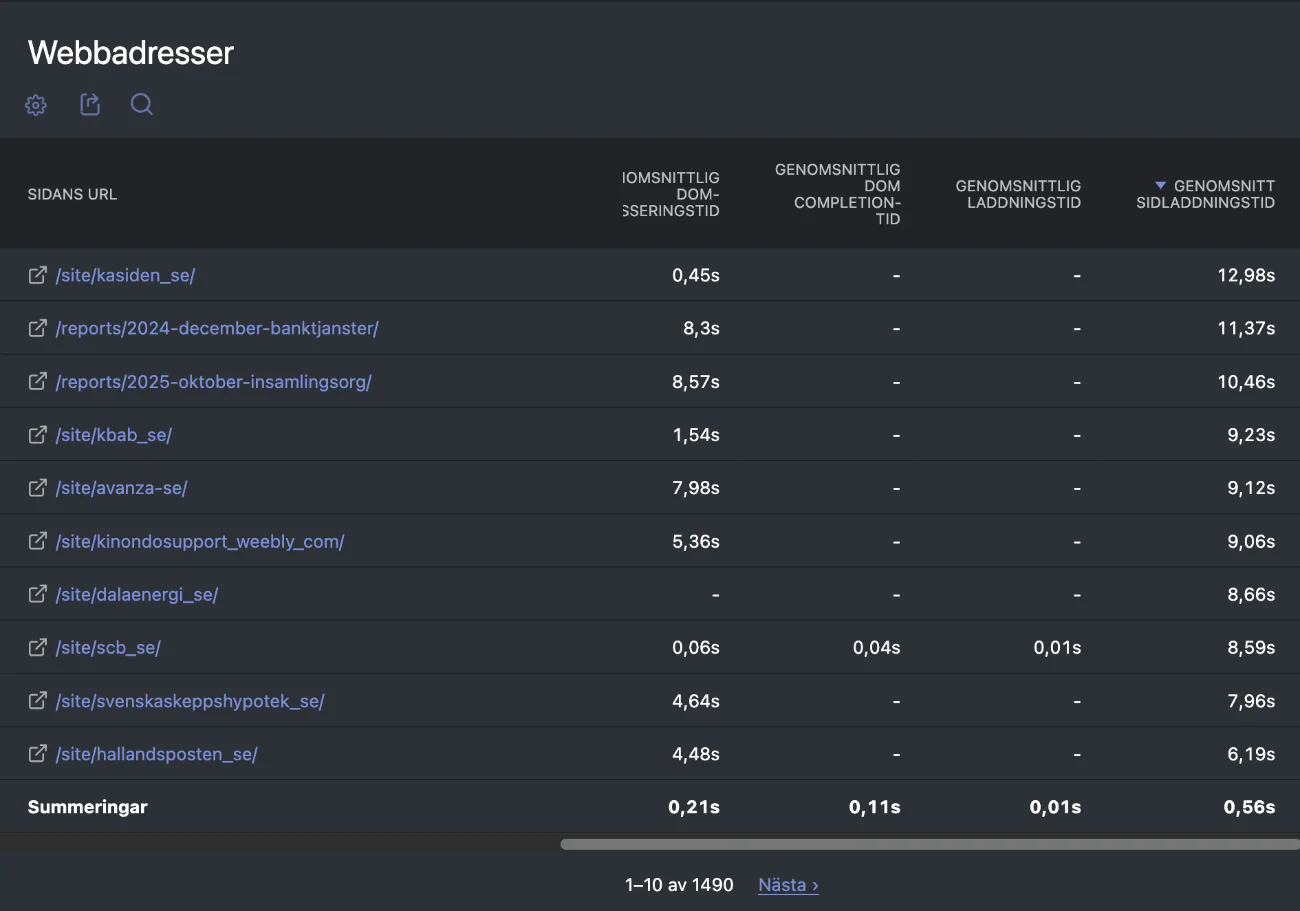
Här ställs vi inför det klassiska problemet mellan kvantitativa och kvalitativa mått. Sidan högst upp i listan, Stiftelsen K A Almgren sidenväveri, var förvisso väldigt långsam, men det drabbade bara en enda användare och det kanske inte ens hade med webbplatsen att göra. Så det blir lite av ett hoppande mellan storheter här. Tittar jag längre ner i listan finns det i alla fall ibland ett tiotal eller ett tjog med sidvisningar som i genomsnitt tog flera sekunder att bli helt färdiga.
Och det här är nog egentligen inte ett problem så som jag ser det. För vi ska hämta ut all denna data via Matomos API och bearbeta det. Så vi kan välja en miniminivå av unika sidvisningar för det vi vill kolla på mer nogrannt.
Exportera RUM-prestanda från Matomo och fortsätt med Webperf Core
Dessa moment kommer vi göra nu:
- Hämta ut information om långsamma sidor via Matomos API.
- Skapa en sites.json för de sidor vi vill kunna testa med Webperf Core.
- Kör Lighthouse-testet på vår sites.json för att samla in syntetisk prestandadata.
- Bearbeta våra data, leta efter fynd och potential.
För att hämta ut data från Matomos API behöver du det som kallas för en token
. Det är lite som ett lösenord och om du tidigare hört talas om API-nyckel så är det samma sak.
→ What is the token_auth and where can I find this token to use in the API calls? (Matomo)
På Matomo-språk är det specifikt Analytics Web API vi kommer använda.
“… used to request all Matomo reports and to manage (add, update, delete) websites, users, permissions, email reports, etc.”
En token är personlig i Matomo och du hittar den under Administration → Personligt → Säkerhet, där kommer du hitta knappen Skapa ny token
. Du får ange lite uppgifter om din token och när du sparat kommer du få en lång sträng som du ska spara ner någonstans.
Så hur hittar man data i Matomo? Det är så fiffigt att där man är van att se olika tabeller med data finns det vi söker i exportfunktionen.
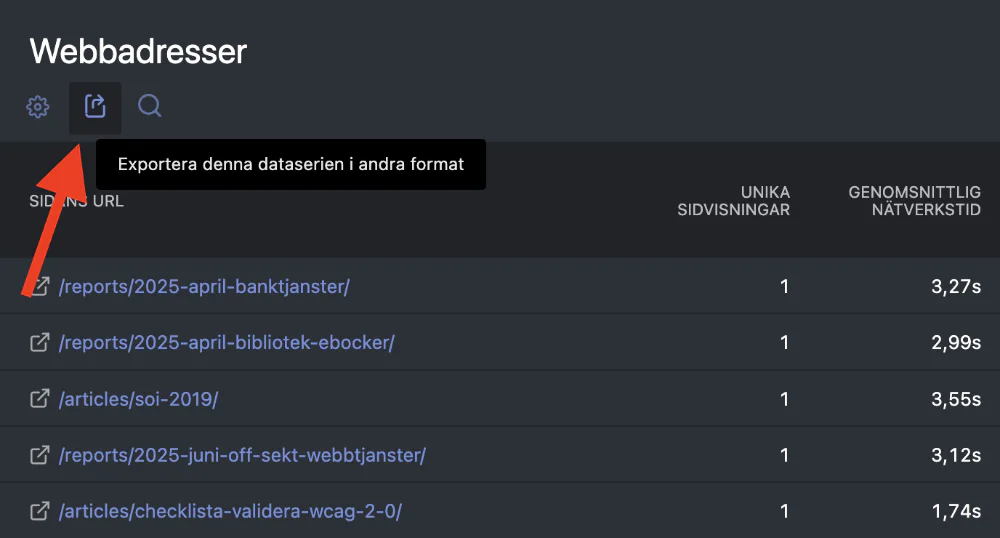
När man klickar där kommer en modal-ruta fram. Det är inte glasklart kanske men det är en kombination av saker att ställa in. Json vill vi ha som format, Rapport med metadata och Allt. Efter det klickar vi på den diskreta Visa exportadress
. Se nedan bild.
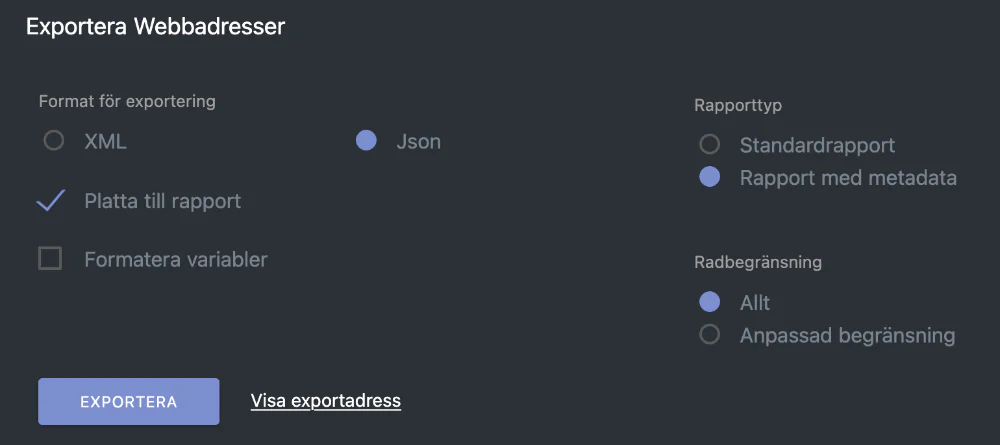
Exportadressen är olika beroende på vilken plats du har din Matomo. För mig ser den ut så här:
https://stats.tba.nu/index.php?module=API&format=JSON&idSite=8&period=day&date=today&method=API.getProcessedReport&apiModule=Actions&apiAction=getPageUrls&flat=1&showMetadata=0&token_auth=ENTER_YOUR_TOKEN_AUTH_HERE&filter_limit=-1
Notera ENTER_YOUR_TOKEN_AUTH_HERE
. När du användet den här adressen, en så kallad API-endpoint, behöver du stoppa in den token du tidigare hämtade ut där. Mer än så behövs inte för att få ut prestandadata ur Matomo i ett strukturerat format. Ifall du vill göra det här på en annan Matomo-egendom på samma server är det bara idSite=8
i mitt fall som behöver ändras.
Notera också att i nedan kodexempel behöver du inte ange hela den här adressen. Men den är bra om du ska göra enkla kontroller direkt i webbläsaren.
Obs! Börja med att ladda ner Webperf Core till din dator och gå in i den mappen. Allt nedan utgår från att du fått Webperf Core att fungera och skapar nya filer i den mappen.
→ Getting started with webperf_core (Github)
Programmatiskt hämta Matomo-data
Om vi i Python ansluter till Matomo skulle det kunna se ut så här för att se att vi når fram till Matomo-rapporten:
import requests
matomo_token = 'xyz'
site_id = 8
data = {
'token_auth': matomo_token
}
params = {'module': 'API', 'format': 'JSON', 'idSite': site_id, 'period': 'month', 'date': 'today', 'method': 'Actions.getPageUrls', 'expanded': '1', 'filter_limit': '-1', 'flat': '1'}
r = requests.post('https://stats.tba.nu/index.php', params=params, data=data)
print(r.status_code)
Notera att det finns en rad med matomo_token
, där ska du byta ut xyz
med din token. Samma med site_id
där hittar du din siffra efter idSite=
i den URL du hämtade i din Matomo. Och där det står stats.tba.nu
byter du till din egen Matomo-adress.
Om du lägger denna kod i en fil du kallar app.py
och kör den med python app.py bör du se det kortfattade meddelandet att statuskoden är 200
. Det betyder att allt gick bra. Om du inte får det kanske du fick 401 och det betyder att det är något fel med din token så som Matomo tar emot den.
Välja ut sidor att fokusera på
När du tittar på denna data, vilket du gör med print(r.text) i Python, kommer du märka att det för enskilda sidor finns massor med data. Det ser ut så här för undersidan med URL /category/kommuner/:
{
"label": "/category/kommuner/",
"nb_visits": 94,
"nb_hits": 128,
"sum_time_spent": 3543,
"nb_hits_with_time_network": 125,
"min_time_network": "0.0000",
"max_time_network": "1.1410",
"nb_hits_with_time_server": 125,
"min_time_server": "0.0000",
"max_time_server": "0.8680",
"nb_hits_with_time_transfer": 123,
"min_time_transfer": "0.0000",
"max_time_transfer": "0.0490",
"nb_hits_with_time_dom_processing": 115,
"min_time_dom_processing": "0.0080",
"max_time_dom_processing": "1.1000",
"nb_hits_with_time_dom_completion": 0,
"min_time_dom_completion": null,
"max_time_dom_completion": null,
"nb_hits_with_time_on_load": 0,
"min_time_on_load": null,
"max_time_on_load": null,
"entry_nb_visits": 41,
"entry_nb_actions": 123,
"entry_sum_visit_length": 3340,
"entry_bounce_count": 15,
"exit_nb_visits": 35,
"sum_daily_nb_uniq_visitors": 94,
"sum_daily_entry_nb_uniq_visitors": 41,
"sum_daily_exit_nb_uniq_visitors": 35,
"nb_hits_following_search": 1,
"avg_time_network": 0.03,
"avg_time_server": 0.067,
"avg_time_transfer": 0.004,
"avg_time_dom_processing": 0.156,
"avg_time_dom_completion": 0,
"avg_time_on_load": 0,
"avg_page_load_time": 0.257,
"avg_time_on_page": 28,
"bounce_rate": "37 %",
"exit_rate": "37 %",
"url": "https://webperf.se/category/kommuner/",
"Actions_PageUrl": "/category/kommuner/",
"segment": "pageUrl==https%253A%252F%252Fwebperf.se%252Fcategory%252Fkommuner%252F"
},
Ur detta kan vi läsa ut att det varit 94 unika sidvisningar, 128 sidvisningar, avvisningsfrekvens på 37%. Och en massa prestandastatistik. Mätvärdet jag fokuserar på heter i JSON-formatet avg_page_load_time och är detsamma som Genomsnitt sidladdningstid
i Matomos användargränssnitt. Det mätvärdet definieras så här i Matomo:
“Genomsnittlig tid (i sekunder) det tar från att begära en sida tills sidan återges helt i webbläsaren.”
Det går att problematisera det mätvärdet genom att orda för andra mätvärden som mäter positiva tillstånd tidigare i användarens upplevelse, exempelvis First Contentful Paint (FCP), men det är en diskussion för en annan bloggpost. Laddtid är tillräckligt bra och det är något som Matomo mäter hela tiden för användarna, vilket gör det till ett intressant RUM-mätvärde bara av den anledningen.
Nästa steg är att välja ut de sidor om har tillräckligt många besök för att vara intressanta att utvärdera. I nedan kodexempel med Python är det de sidor som under innevarande månad har 25 st eller fler unika sidvisningar som väljs ut. Men om du har en webbplats med betydligt många fler besökare är det > 25 i slutet av koden du behöver justera.
app.py
import requests
import json
from datetime import datetime
matomo_token = 'xyz'
site_id = 8
site_url = "https://webperf.se"
data = {
'token_auth': matomo_token
}
params = {'module': 'API', 'format': 'JSON', 'idSite': site_id, 'period': 'month', 'date': 'today', 'method': 'Actions.getPageUrls', 'expanded': '1', 'filter_limit': '-1', 'flat': '1'}
r = requests.post('https://stats.tba.nu/index.php', params=params, data=data)
# Filtrera data
response_data = r.json()
filtered_data = [item for item in response_data if item.get('nb_visits', 0) > 25]
# Bygg sites-struktur
sites = {
"sites": [
{
"id": idx + 1,
"url": site_url.rstrip('/') + item['label']
}
for idx, item in enumerate(filtered_data)
]
}
# Spara till datumbaserad fil
filename = datetime.now().strftime('%Y-%m-%d') + '-sites.json'
with open(filename, 'w', encoding='utf-8') as f:
json.dump(sites, f, indent=4, ensure_ascii=False)
Nu kommer du ha en JSON-fil bredvid din app.py och den kommer ha ett datum i filnamnet, exempelvis 2025-10-31-sites.json och innehålla något som liknar det här:
{
"sites": [
{
"id": 1,
"url": "https://webperf.se/"
},
{
"id": 2,
"url": "https://webperf.se/category/kommuner/"
},
{
"id": 3,
"url": "https://webperf.se/sites/"
}
]
}
Det här är grunden för att kunna köra de olika testerna från Webperf Core på en utvald mängd sidor på en webbplats. Ifall du har den här nyskapade JSON-filen i din mapp med Webperf Core kan du köra ett argument som det nedan för att göra syntetiska prestandatester på samma populära adresser som enligt RUM-data visat sig ha problem.
Testa problematiska sidor syntetiskt
Så här ser anropet ut till Webperf Core som kommer köra det Lighthouse-testet i det här fallet:
python default.py -t 30 -i 2025-10-31-sites.json -r -L sv -o 2025-10-31-results-sites.json
2025-10-31-sites.json är namnet på din fil som skapats av app.py. 2025-10-31-results-sites.json är filnamnet du vill ha för ditt testresultat.
Se till att din *-results-sites.json ligger i samma katalog som nedan fil analyse.py
Skapa enkel rapport i Markdown
Ifall du följer ovanstående kodexempel kommer det finnas en fil som heter 2025-10-31-results-sites.json
i mappen som heter webperf_core. Skapa nedan fil med namn analyse.py bredvid denna resultatfil.
analyse.py
import json
from datetime import datetime
from typing import Dict, List
def load_data(results_file: str, sites_file: str):
"""Ladda JSON-filer"""
with open(results_file, 'r', encoding='utf-8') as f:
results_data = json.load(f)
with open(sites_file, 'r', encoding='utf-8') as f:
sites_data = json.load(f)
return results_data, sites_data
def analyze_performance_issues(results_data: Dict, sites_data: Dict) -> Dict[str, List[Dict]]:
"""
Analysera performance-problem från Webperf Core
Args:
results_data: Test-resultat från Webperf Core
sites_data: Sites med URL-mappning
Returns:
Dictionary med URL som nyckel och lista av performance-problem
"""
site_urls = {site['id']: site['url'] for site in sites_data['sites']}
sites_with_problems = {}
for test in results_data['tests']:
site_id = test['site_id']
url = site_urls.get(site_id, f"Site {site_id}")
problems = []
# Hitta groups-data (kan vara olika nycklar beroende på domän)
data = test.get('data', {})
groups = data.get('groups', {})
# Iterera genom alla groups
for group_name, group_data in groups.items():
issues = group_data.get('issues', [])
for issue in issues:
# Endast performance-kategori
if issue.get('category') != 'performance':
continue
# Kolla subIssues för detaljer
sub_issues = issue.get('subIssues', [])
for sub_issue in sub_issues:
severity = sub_issue.get('severity', '')
# Skippa resolved issues
if severity == 'resolved':
continue
# Endast warnings och errors är intressanta
if severity in ['warning', 'error']:
problems.append({
'severity': severity,
'rule': sub_issue.get('rule', 'Unknown'),
'text': sub_issue.get('text', 'No description')
})
if problems:
sites_with_problems[url] = problems
return sites_with_problems
def generate_report(sites_with_problems: Dict, total_sites: int, filename: str = None) -> str:
"""
Generera Markdown-rapport
Args:
sites_with_problems: Dictionary med problem per site
total_sites: Totalt antal testade sidor
filename: Namn på rapportfil
Returns:
Filnamn för den genererade rapporten
"""
if filename is None:
filename = datetime.now().strftime('%Y-%m-%d') + '-performance-rapport.md'
with open(filename, 'w', encoding='utf-8') as f:
f.write("# Webbprestandarapport (Webperf Core)\n\n")
f.write(f"**Datum:** {datetime.now().strftime('%Y-%m-%d %H:%M')}\n\n")
f.write("## Sammanfattning\n\n")
f.write(f"Analysen visar att **{len(sites_with_problems)} av {total_sites} sidor** "
f"har performance-problem.\n\n")
if sites_with_problems:
f.write("## Detaljerade resultat\n\n")
for url, problems in sites_with_problems.items():
f.write(f"### {url}\n\n")
f.write(f"**Antal problem:** {len(problems)}\n\n")
f.write("| Severity | Regel | Beskrivning |\n")
f.write("|----------|-------|-------------|\n")
for p in problems:
severity_icon = "⚠️" if p['severity'] == 'warning' else "❌"
f.write(f"| {severity_icon} {p['severity']} | `{p['rule']}` | {p['text']} |\n")
f.write("\n")
else:
f.write("Inga problem hittades! ?\n")
return filename
def main():
"""Huvudfunktion"""
# Konfigurera filnamn
results_file = f'2025-10-31-results-sites.json'
sites_file = f'2025-10-31-sites.json'
print(f"Laddar data från {results_file}...")
try:
results_data, sites_data = load_data(results_file, sites_file)
print(f"✓ Laddade {len(results_data['tests'])} tester")
print("\nAnalyserar performance-problem...")
problems = analyze_performance_issues(results_data, sites_data)
print(f"✓ Hittade problem på {len(problems)} sidor")
report_file = generate_report(problems, len(sites_data['sites']))
print(f"✓ Rapport skapad: {report_file}")
except FileNotFoundError as e:
print(f"❌ Fel: Kunde inte hitta fil - {e}")
except Exception as e:
print(f"❌ Fel vid analys: {e}")
if __name__ == "__main__":
main()
Var noga med filnamnen i slutet av koden. Alltså results_file och sites_file. Om du gav filen namnet analyse.py
kör du med python analyse.py i din terminal eller kommandotolk.
Hur ser rapporten ut? Ifall du gör en förhandsvisning av din markdown-fil kan den se ut som nedan.
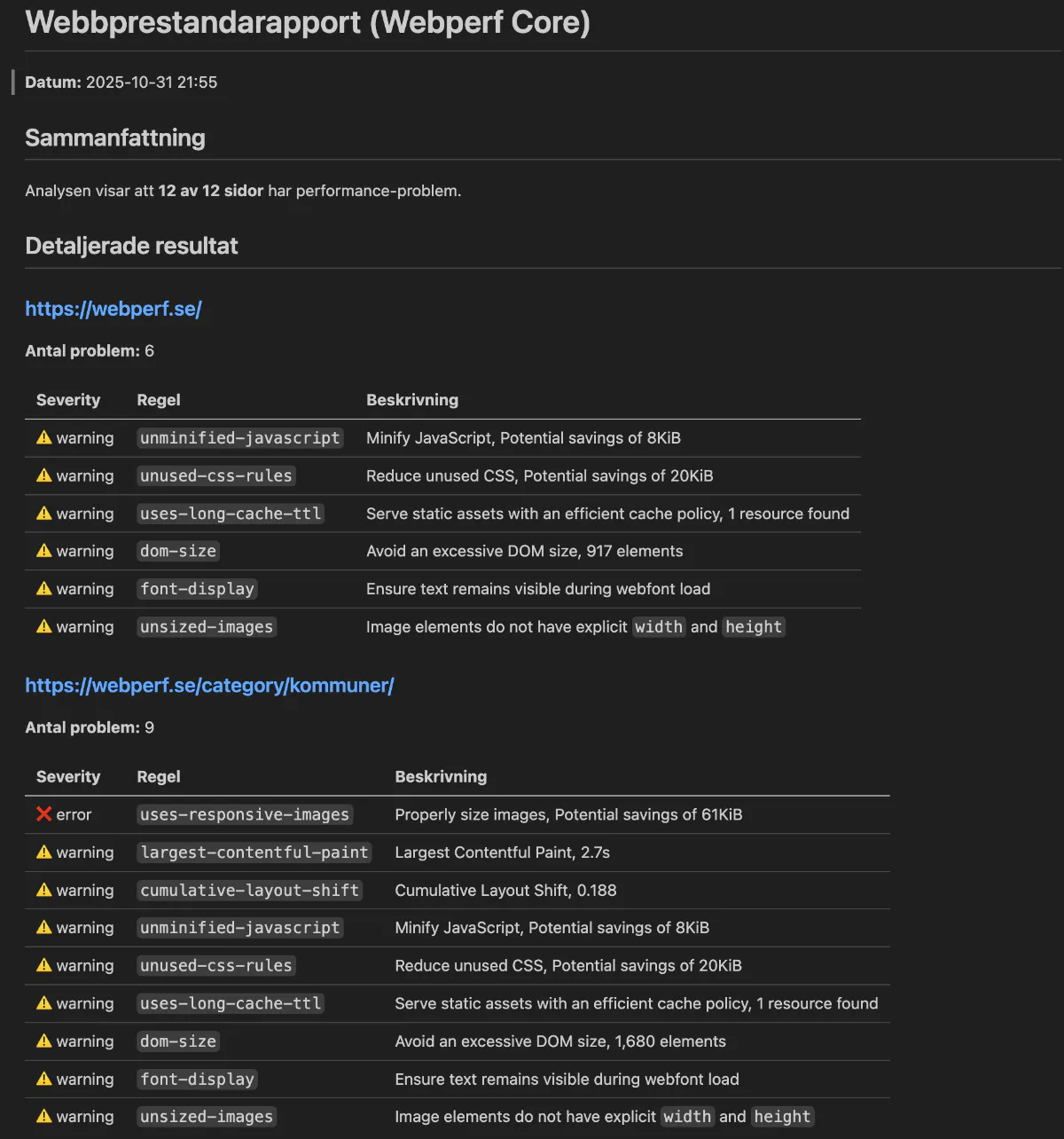
Det här är i markdown-format och enkelt att formatera till HTML eller vad du nu vill ha. Inställningarna är att bara lista saker som enligt Lighthouse är så pass dåligt att de är antingen en varning eller direkt fel. Detta kan du förstås laborera med efter var din webbplats är på att bli bättre på prestanda.
Ladda ner Python-kod och exempelfiler
- 2025-10-rum-data-matomo-och-webperf.zip (zip-arkiv, 2 Mb)



